From higher-resolution imaging to genome-sized DNA molecules built from scratch, the year ahead looks exciting for life-science technology.

An automated bioreactor system for growing yeast, which can be used to investigate synthetic genomes — one area poised to make big strides this year.Credit: Tim Llewellyn/Ginkgo Bioworks
Seven specialists forecast the developments that will push their fields forward in the year ahead.
SARAH TEICHMANN: Expand single-cell biology
Head of cellular genetics, Wellcome Trust Sanger Institute, Hinxton, UK.
In the past ten years, we have seen a huge increase in the number of single cells that researchers can profile at one time. That’s going to continue, mainly because of improvements in cell-capture technologies, methods that label cells with barcodes and smarter ways of combining existing technologies.
Such increases might sound mundane, but they allow us to do different kinds of experiment and to study more complex samples at higher resolution. Instead of just focusing on one person, for instance, researchers will be able to look at samples from 20 or 100 people at once. That means we’ll be able to get a better grip on population diversity. We’ll also be able to profile more developmental time points, tissues and individuals, enabling us to increase the statistical significance of our analyses.
Our lab has just participated in an effort that profiled 250,000 cells across 6 species, showing that the genes responsible for the innate immune response evolve rapidly and have high cell-to-cell variability across species — both features that help the immune system to produce an effective and fine-tuned response1.
We’re also going to see developments in our ability to look at different genome modalities at the same time in single cells. Rather than limiting ourselves to RNA, for instance, we’ll be able to see whether the protein–DNA complex called chromatin is open or closed. That has implications for understanding the epigenetic status of cells as they differentiate, and of epigenetic memory in the immune and nervous systems.
There’ll also be an evolution in methods of linking single-cell genomics to phenotype — for instance, in ways to link protein expression or morphology to a given cell’s transcriptome. I think we’ll see more of that type of thing in 2019, whether through pure sequencing or through imaging and sequencing combined. Indeed, we have been witnessing a kind of convergent evolution of both technologies: sequencing is gaining in resolution and imaging is becoming multiplexed.
JIN-SOO KIM: Improve gene editors
Director of the Center for Genome Engineering, Institute for Basic Science, and professor of chemistry, Seoul National University.
Protein engineering now drives genome engineering. The first-generation CRISPR gene-editing systems used the nuclease Cas9, an enzyme that cuts DNA at specific sites. This combination is still widely used, but many engineered CRISPR systems are replacing the naturally occurring nucleases with new variants, such as xCas9 and SpCas9-NG. These broaden the targeting space — the regions of the genome that can be edited. Some are also more specific than the first-generation enzymes, and that can minimize or avoid off-target effects.
Last year, researchers reported fresh obstacles hindering the introduction of CRISPR genome editing into clinics. These include activation of the p53 gene (which is linked to cancer risk); unexpected ‘on-target’ effects, such as large deletions; and immunogenicity against CRISPR systems2–4. To use genome editing for a clinical application, these limitations must be addressed. Some of these issues are caused by DNA double-strand breaks. But not all genome-editing enzymes create double-strand breaks — ‘base editors’ convert single DNA letters directly to another letter. As a result, base editing is both cleaner than conventional genome editing, and more efficient. Last year, researchers in Switzerland used base editors to correct a gene mutation in mice that causes phenylketonuria, a build-up of toxins5.
But base editors are limited in the sequences they can edit, which are defined by a sequence called a protospacer adjacent motif. Protein engineering can be used to redesign and improve current base editors and might even create new editors, such as a recombinase fused to inactivated Cas9. Like base editors, recombinases do not induce double-strand breaks, but can insert desired sequences at user-defined locations. RNA-guided recombinases are sure to expand genome editing in a new dimension.
The routine use of gene-editing techniques in the clinic might still be several years away. But we will see a new generation of tools in the next year or two: there are so many researchers interested in this technology, using it every day. Fresh problems crop up, but so, too, do innovative solutions. I expect to be surprised.
XIAOWEI ZHUANG: Boost microscopy resolution
Professor of chemistry and chemical biology, Harvard University, Cambridge, Massachusetts; and 2019 Breakthrough Prize winner.
The proof-of-principle demonstrations in super-resolution microscopy happened just a decade or two ago, but today the technique is relatively commonplace and accessible to biologists — and has led to a boom of knowledge.
One particularly exciting area of research is determining the 3D structure and organization of the genome. It is increasingly obvious that the genome’s 3D structure plays an important part in regulating gene expression.
In the past year, we have reported work in which we imaged chromatin (which forms chromosomes) with nanometre-scale precision, linking it to sequence information across thousands of cells of different types6. This spatial resolution was one to two orders of magnitude better than our previous work, and enabled us to observe that individual cells organize their chromatin into domains that vary greatly from cell to cell. We also provided evidence as to how those domains form, which leads us to a better understanding of the mechanisms of chromatin regulation.
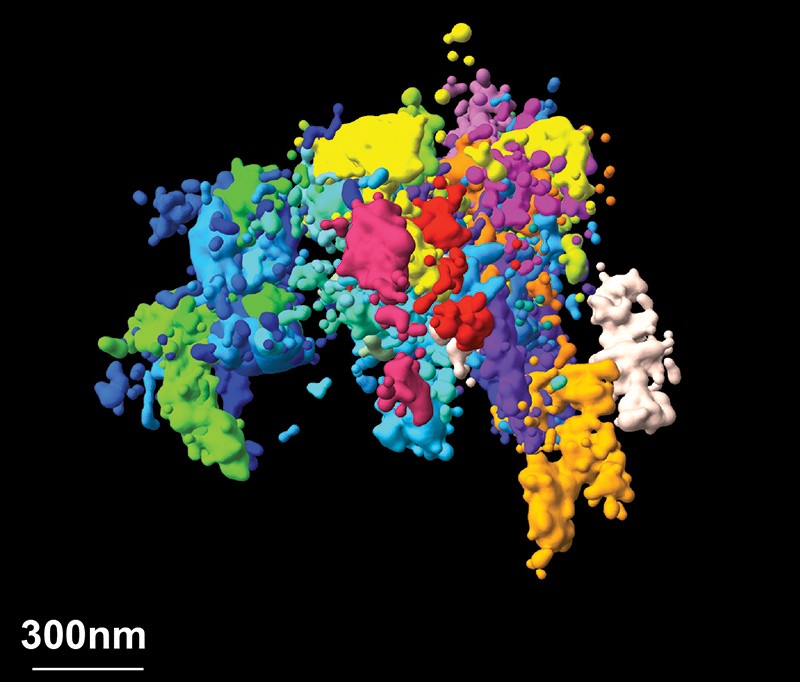
Super-resolution microscopy is bringing chromatin — a 3D complex of DNA and protein — into focus.Credit: Bogdan Bintu, The Xiaowei Zhuang Laboratory, The Alistair Boettiger Laboratory, Science 362, eaau1783 (2018)
Beyond chromatin, I foresee substantial improvements in spatial resolution across the field of super-resolution imaging. Most experiments operate at a resolution of a few tens of nanometres — small, but not compared with the molecules being imaged, particularly when we want to resolve molecular interactions. But we are seeing improvements in fluorescent molecules and imaging approaches that substantially increase resolution, and I expect that imaging at 1-nanometre resolution will become routine.
At the same time, temporal resolution is getting better and better. At the moment, researchers must compromise between spatial resolution and imaging speed. But with better illumination strategies and faster image acquisition, those limitations could be overcome. Tens of thousands of genes and other types of molecule function collectively to shape a cell’s behaviour. Being able to watch these molecules in action simultaneously at the genomic scale will create powerful opportunities for imaging.
HONGKUI ZENG: Map brain connections
Executive director of structured science, Allen Institute for Brain Science, Seattle, Washington.
The connections between individual cells and various cell types are so complex that mapping their connectivity at the global and population level is no longer sufficient to understand them. So, we are mapping connections based on cell type and at the single-cell level.
We can accomplish this with ‘anterograde’ and ‘retrograde’ tracing, which reveal the structures that protude from specific cells, called axon projections. We are also using more methods based on single-neuron morphology, looking at where the projections arise and terminate for individual neurons.
A big advance is the generation of electron microscopy data sets that cover substantially larger volumes than has been possible before. At the Howard Hughes Medical Institute’s Janelia Research Campus in Ashburn, Virginia, for instance, researchers are working to map every neuron and synapse in the Drosophila fruit fly.
Improvements in image acquisition and sample handling are key for these advances; so, too, are improvements in computing. At the Allen Institute for Brain Science, we are involved in an effort to build a virtual map of mouse brain neural connectivity with the help of machine-learning algorithms.
Tremendous specificity is encoded in the brain’s connections. But without knowing that specificity at both global and local scales, our ability to understand behaviour or function is essentially based on a black box: we lack the physical foundations to understand neuronal activity and behaviour. Connectomics will fill in that missing ‘ground-truth’ information.
JEF BOEKE: Advance synthetic genomes
Director of the Institute for Systems Genetics, New York University Langone Medical Center, New York City.
When I realized that it would be possible to write a whole genome from scratch, I thought it would be a great opportunity to get a fresh perspective on genome function.
From a pure science point of view, groups have made progress in synthesizing simple bacterial and yeast genomes. But technical challenges remain in synthesizing entire genomes, especially mammalian ones.
One advance that will help, but that hasn’t yet hit the marketplace, is technology for reducing the cost of DNA synthesis. Most DNA synthesis that happens today is based on a process called phosphoramidite chemistry. The resulting nucleic-acid polymers are limited, in terms of both their maximum length and their fidelity. It’s kind of a miracle that it works as well as it does.
A number of companies and laboratories are pursuing enzymatic DNA synthesis — an approach that has the potential to be faster, more accurate and less expensive than chemical synthesis. No company yet offers such molecules commercially. But last October, a Paris-based firm called DNA Script announced that it had synthesized a 150-base oligonucleotide, nearly matching the practical limits of chemical DNA synthesis. We are all waiting to hear more about that.
As a community, we have also worked out how to assemble large segments of human chromosomal DNA, and we can build regions of 100 kilobases or more using this method. Now we are going to use this approach to dissect large genomic regions that are known to be important in discerning disease susceptibility, or that underlie other phenotypic traits.
We can synthesize these regions rapidly in yeast cells, so we should be able to make tens to hundreds of genomic variants that previously would have been impossible to test. Using them, we will be able to examine the thousands of genomic loci implicated in genome-wide association studies as having some significance in disease susceptibility. This dissection strategy might enable us to finally start pinning down just what these variants do.
VENKI RAMAKRISHNAN: Reveal molecular structure
Structural biologist, MRC Laboratory of Molecular Biology, Cambridge, UK.
Understanding structure is a key step to understanding function. Cryo-electron microscopy (cryo-EM) enables researchers to determine high-resolution structures using smaller and less-pure samples than ever before. This means that not only can we see structures that were never previously possible to observe, but we can also study more challenging problems, such as the dynamics of protein complexes or different states in biochemical pathways.
Right now, cryo-EM as a field is roughly where crystallography was in the 1960s or 1970s. The first wave of technology has happened, but it’s still advancing tremendously. The next generation of detectors, such as those being developed by design engineer Nicola Guerrini and her colleagues at the Science and Technology Facilities Council in Swindon, UK, will provide better signals and allow us to see even smaller molecules.
Already, we have seen many exciting structures, including one from the groups of neuroscientist Michel Goedert and structural biologist Sjors Scheres at the MRC Laboratory of Molecular Biology. They imaged filaments of a protein called tau, unexpectedly finding that it exhibits distinct protein folds in different types of dementia, including Alzheimer’s disease7.
A second area of development is sample preparation. In cryo-EM, a small amount of the molecule in solution goes on a fine wire mesh, the excess is wiped off and the thin remaining layer is frozen. But molecules at the air–water interface can denature, or fall apart. Also, electrons that hit the sample can charge the molecules, causing them to move and blur. A lot of people are working to minimize these effects to give stable samples that can be measured more accurately.
With these advances, we should be able to watch molecular events as they happen in the cell and on its surface. We might be able to observe the complicated cycle of conformational changes in processes such as DNA replication or splicing, getting a feel for the entire molecular process.
CASEY GREENE: Apply AI and deep learning
Assistant professor of systems pharmacology and translational therapeutics, Perelman School of Medicine, University of Pennsylvania, Philadelphia.
Life scientists have become adept at using deep-learning software and artificial intelligence (AI) to build predictive models that tell us, for example, where to find the motifs to which gene regulatory elements bind. But now we want models that reveal deeper truths — for instance, the details of gene regulation itself and why certain genetic features are important.
What I’m most excited about in the coming year are computational approaches that are robust enough to be used across the wealth of random genomic data that people upload when they publish a paper. One exciting technique for doing that is transfer learning.
Using this approach, you can apply data sets that are only tangentially relevant to a problem to learn the broad characteristics of that problem, and then apply what the algorithm learnt to analyse data sets that you care about. In a study published last year, for example, we wanted to train a model using data sets for a rare disease called anti-neutrophil cytoplasmic antibody-associated vasculitis. But there weren’t enough data to do that. So, we trained our model on RNA-sequencing data from more than 1,400 other studies instead, and applied that model to our disease, revealing gene networks related to immune and metabolic function that contribute to the disease’s symptoms8. I expect to see more papers on this before long, in which transferring models enables new science.
One day, I hope, these approaches will not only provide a predictive model for specific scenarios and answers to specific problems, but also reveal what is happening, biologically, to produce the data that we see. I expect that there will be steps towards this over the next year, but it’s going to require a lot of investment in techniques and resources that aid model interpretation. If we’re there in five years, I’ll be thrilled.
(원문: 여기를 클릭하세요~)